
plotly를 활용한 꺾은선그래프 - plotly.express
들어가며
plotly는 인터랙티브한 그래프를 그릴 수 있는 그래픽 패키지입니다. 기본적으로 모든 차트를 대화형으로 지원하여, 세부 정보 표시, 확대 등이 가능합니다. 이 글에서는 plotly를 활용한 꺾은선그래프를 생성하고, 커스터마이징 하는 방법을 소개합니다.
예제로 활용할 데이터는 kaggle의 기상에 관한 데이터 셋입니다. 아래 링크를 참고하세요.
Weather Long-term Time Series Forecasting
20 Meteorological Indicators Observed Every 10 Minutes in 2020
www.kaggle.com
먼저 필요한 패키지를 import하고 데이터를 df에 저장합니다.
import pandas as pd
import plotly.express as px
df = pd.read_csv('cleaned_weather.csv')
df.head()
- 꺾은선그래프
- 꺾은선그래프 - x축, y축, 그래프 제목 변경
- 꺾은선그래프 - 선 스타일 변경
- 꺾은선그래프 - 마커 추가
- 꺾은선그래프 - 2개 이상의 변수
꺾은선그래프
먼저 필요한 패키지를 import하고, 그래프로 표출하기 위한 집계 데이터를 생성합니다. 위의 df를 활용하여 월별 평균 온도를 summary_df에 저장합니다.
summary_df = df.copy()
summary_df['date'] = pd.to_datetime(summary_df['date'], format="%Y-%m-%d %H:%M:%S",errors='coerce')
summary_df['yyyymm'] = summary_df['date'].dt.strftime('%Y%m')
summary_df = summary_df.groupby(['yyyymm'])['T'].mean().reset_index()
summary_df.head()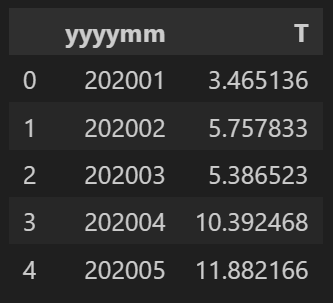
기본 꺾은선그래프를 생성하는 방법은 다음과 같습니다. 데이터프레임의 이름과 표현하고자 하는 변수명을 x와 y에 각각 설정하면 됩니다.
fig = px.line(summary_df,
x='yyyymm',
y='T',
)
fig.show()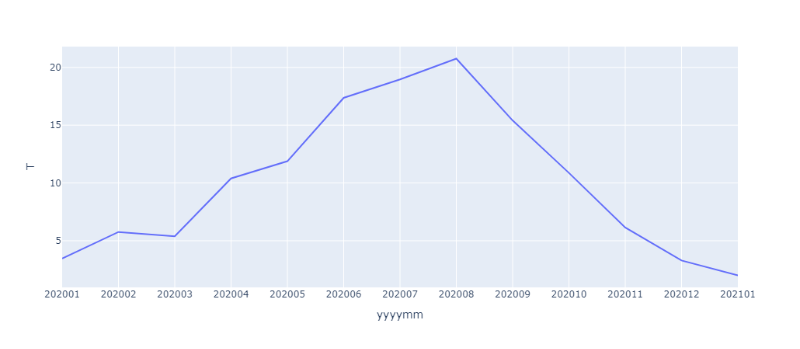
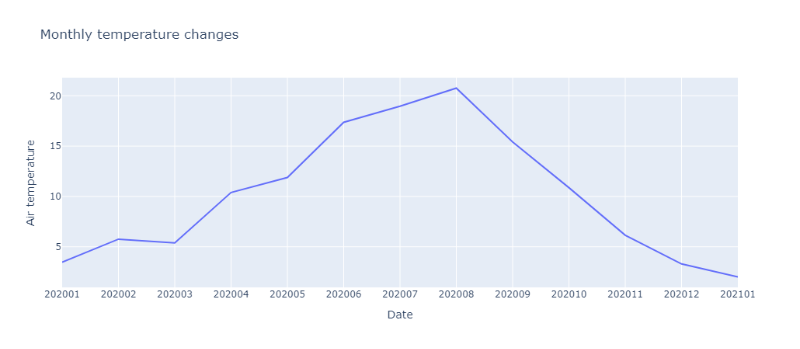
꺾은선그래프 - x축, y축, 그래프 제목 변경
꺾은선그래프에 x축, y축 제목을 추가하는 옵션은 update_xaxes, update_yaxes입니다. 각각의 축에 맞게 원하는 제목을 설정합니다. 그래프의 제목을 추가하는 옵션은 title입니다. title에 원하는 제목을 설정합니다.
꺾은선그래프 - 선 스타일 변경
꺾은선그래프의 선 스타일을 변경하는 옵션은 update_traces입니다. 원하는 스타일에 맞게 width와 dash를 설정합니다.
fig = px.line(summary_df,
x='yyyymm',
y='T',
title="Monthly temperature changes",
)
fig.update_traces(line=dict(width=2, dash='dot'))
fig.update_xaxes(title_text="Date")
fig.update_yaxes(title_text="Air temperature")
fig.show()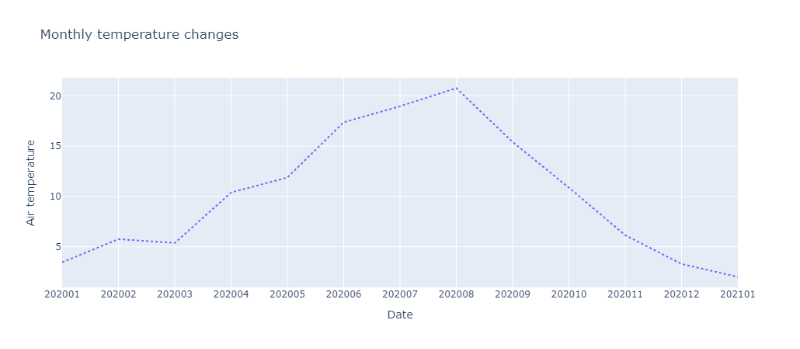
꺾은선그래프 - 마커 추가
꺾은선그래프의 마커를 추가하는 옵션은 markers입니다. 마커를 표시하고 싶은 경우 True로 설정합니다. 디폴트는 False입니다.

꺾은선그래프 - 2개 이상의 변수
2개 이상의 변수를 표현하기 위해 월별 기온의 최솟값과 최댓값을 집계하는 summary_df2를 생성하겠습니다.
summary_df2 = df.copy()
summary_df2['date'] = pd.to_datetime(summary_df2['date'], format="%Y-%m-%d %H:%M:%S",errors='coerce')
summary_df2['yyyymm'] = summary_df2['date'].dt.strftime('%Y%m')
summary_df2 = summary_df2.groupby(['yyyymm'])['T'].agg(['min', 'max']).reset_index()
summary_df2.rename(columns={'min':'temp_min', 'max':'temp_max'}, inplace=True)
summary_df2.head()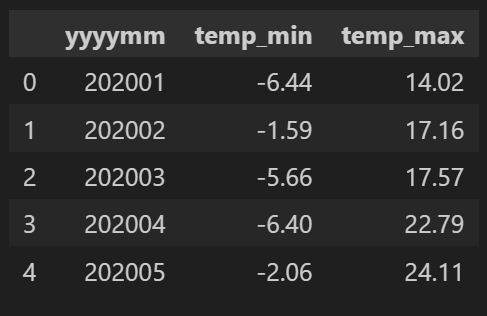
2개 이상의 변수를 표현할 경우에는 다음과 같이 표현하고자 하는 변수를 y에 설정합니다. (아래 그래프의 경우, 2021년 1월의 데이터가 1 row만 존재하여 최솟값과 최댓값이 동일하게 나왔습니다.)
fig = px.line(summary_df2,
x='yyyymm',
y=['temp_min','temp_max'],
title="Monthly temperature changes",
markers=True
)
fig.update_xaxes(title_text="Date")
fig.update_yaxes(title_text="Air temperature")
fig.show()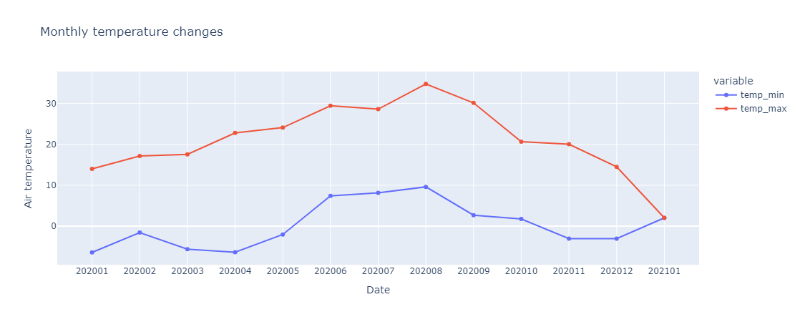
'Python' 카테고리의 다른 글
| [파이썬] PostgreSQL DB 연동 - DB 연결 및 조회, psycopg2 (1) | 2024.11.20 |
|---|---|
| [파이썬] 공공데이터 환율 정보 오픈API xml 파싱, 데이터프레임 변환 - json_normalize() (6) | 2024.11.18 |
| [파이썬] 모듈화를 활용한 함수 호출, 재사용성 증가 (4) | 2024.11.08 |
| [파이썬] plotly를 활용한 막대그래프 - plotly.express (3) | 2024.11.07 |
| [파이썬] 텍스트 빈도 분석을 위한 워드 클라우드(영문) - wordcloud, matplotlib (1) | 2024.10.30 |