
특정 키워드 네이버 뉴스 제목 크롤링 - BeautifulSoup
들어가며
크롤링은 웹사이트에서 자동으로 데이터를 수집하는 기술입니다. 사람이 직접 웹사이트를 클릭하여 데이터를 수집하는 대신, 파이썬 등을 활용하면 편리하게 데이터를 추출할 수 있습니다. 하지만, 서버에 부담을 줄 수 있는 요청은 IP 차단을 초래할 수 있어 조심해야 합니다.
이 글에서는 예제로 '비트코인'에 대한 네이버 뉴스 제목을 크롤링하는 방법을 소개합니다.

키워드, URL 설정
먼저 필요한 패키지인 requests와 BeautifulSoup를 import합니다.
import requests
from bs4 import BeautifulSoup위에서 설명한 대로 검색할 키워드는 '비트코인'으로 설정했습니다. 네이버 뉴스 url은 형식이 잘 갖춰져 있어 크롤링하기 매우 편리합니다.
keyword = '비트코인'
url = f'https://search.naver.com/search.naver?where=news&query={keyword}'위에서 설정한 url인 'https://search.naver.com/search.naver?where=news&query=비트코인'을 검색 창에 그대로 입력하면, 아래 이미지와 같이 '비트코인'에 대한 뉴스를 확인할 수 있습니다.
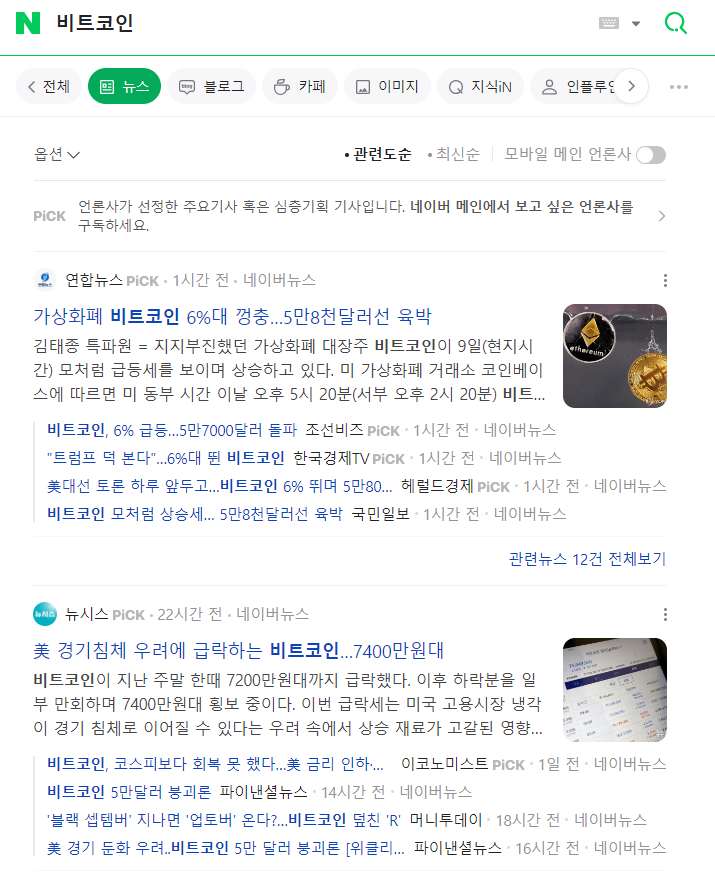
웹 페이지 요청
위의 url로 웹 페이지에 요청을 보내서 응답을 response에 저장합니다. requests.get()은 웹 페이지에 접속하여 해당 페이지의 HTML 코드 전체를 가져오는 코드입니다.
# 웹 페이지 접속
response = requests.get(url)이제 위에서 가져온 HTML 코드(response.text)를 파싱 할 수 있도록 BeautifulSoup를 활용합니다. 위에서 저장한 response는 웹 페이지를 접속하는 부분이고, soup는 웹 페이지를 편리하게 파싱할 수 있도록 도와주는 도구라고 할 수 있습니다.
# HTML 파싱
soup = BeautifulSoup(response.text, 'html.parser')이 글의 최종 목표는 네이버 뉴스 제목을 크롤링하는 것이므로 불러온 HTML 코드(soup)에서 뉴스 제목이 포함된 부분만 articles에 저장하겠습니다. 제목 링크는 공통적으로 data-heatmap-target=".tit" 속성을 갖고 있는 <a> 태그에 존재합니다. 다음과 같이 articles에 해당 <a> 태그로 감싸진 전체 구조를 저장합니다.
※ articles = soup.select('.news_tit') # as-is ----- 2025. 10. 18 수정
articles = soup.select('a[data-heatmap-target=".tit"]')
articles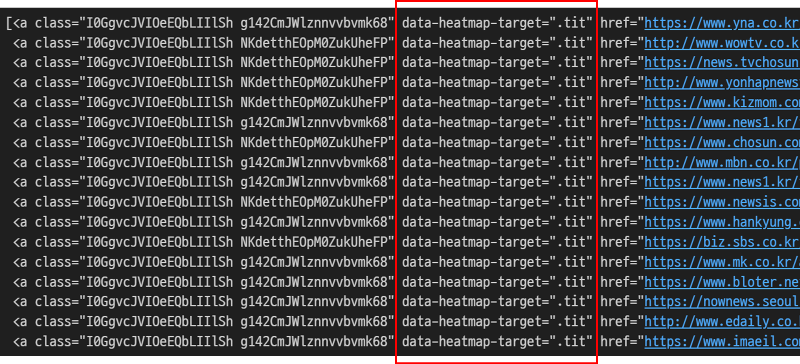
aritcles 중 하나에 대해 뉴스 제목 텍스트를 추출하면 다음과 같습니다.
article = articles[0]
title = article.text
title
뉴스 제목 데이터프레임 생성
articles를 활용하여 뉴스 제목을 데이터프레임으로 정리하면 다음과 같습니다.
import pandas as pd
title_tot = pd.DataFrame([article.text for article in articles], columns=['title'])
title_tot.head()
전체 코드
import requests
from bs4 import BeautifulSoup
import pandas as pd
# 키워드, URL
keyword = '비트코인'
url = f'https://search.naver.com/search.naver?where=news&query={keyword}'
# 웹 페이지 요청
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# 뉴스 제목 포함 부분 필터링
articles = soup.select('a[data-heatmap-target=".tit"]')
articles
# 뉴스 제목 확인
article = articles[0]
title = article.text
title
# 뉴스 제목 데이터프레임 생성
title_tot = pd.DataFrame([article.text for article in articles], columns=['title'])
title_tot.head()
'Python' 카테고리의 다른 글
| [파이썬] TSP Traveling Salesman Problem 문제 해결 - ‘완전 탐색’ 구현 (5) | 2026.04.21 |
|---|---|
| [파이썬] opendataloader-pdf를 활용한 PDF 변환: txt, json, html, markdown (2) | 2025.10.26 |
| [파이썬] 데이터프레임 행, 열 선택 - iloc, loc (8) | 2025.10.04 |
| [파이썬] MongoDB JSON 데이터 import 및 기본 쿼리 - pymongo (3) | 2025.09.08 |
| [파이썬] bokeh를 활용한 인터랙티브 시각화 기초 - 꺾은선, 산점도, 막대 그래프 (0) | 2025.07.16 |