
opendataloader-pdf를 활용한 PDF 변환: txt, json, html, markdown
들어가며
한컴에서 PDF를 TXT, JSON, HTML, 마크다운 Markdown 형태로 변환할 수 있는 기술을 오픈소스로 공개했습니다. 다양한 형태로 변환 가능하고, 빠르고 가볍다는 장점으로 RAG, 벡터 검색 등 AI 기술에 매우 유용하게 활용할 수 있습니다.
이 글에서는 opendataloader-pdf를 활용하여 PDF를 TXT, JSON, HTML, 마크다운 Markdown 형식으로 변환하는 방법을 소개합니다.
opendataloader-pdf에 대한 더 자세한 정보는 아래 링크를 참고해 주세요:)
OpenDataLoader
PDF Data loader for AI/ML datasets. Easily load, explore, and utilize various datasets.
opendataloader.org
패키지 설치
먼저, opendataloader-pdf를 위한 필수 조건은 다음과 같습니다.
◾ Java 11 이상
◾ Python 3.9 이상
위의 필수 조건을 갖췄다면, 다음 명령어를 활용하여 opendataloader-pdf 파이썬 패키지를 설치 후, import 합니다.
# pip install opendataloader-pdf
import opendataloader_pdfPDF 파일 TXT 변환
PDF 파일을 TXT 파일로 변환하는 방법은 다음과 같습니다. format 옵션을 'text'로 설정합니다.
opendataloader_pdf.convert(
input_path=['TemplateEngineIngredientPDF.pdf'],
output_dir='C:/Users/convert_pdf/',
format=['text']
)opendataloader-pdf의 주요 옵션은 다음과 같습니다.
◾ input_path: PDF 파일 혹은 PDF 파일 경로
◾ output_dir: 변환된 결과 파일을 저장할 경로
◾ password: 암호화된 PDF의 비밀번호
◾ format: 변환 형식('json', 'html', 'text' 등)
◾ keep_line_breaks: 텍스트 출력 시 줄 바꿈 유지(Default: False)
TXT 파일로 변환한 결과는 다음과 같습니다. 다음 이미지와 같이 PDF 파일의 표 부분도 텍스트로 깔끔하게 변환된 것을 확인할 수 있습니다.
from pathlib import Path
pdf_to_text = Path('TemplateEngineIngredientPDF.txt').read_text()
print(pdf_to_text)
PDF 파일 JSON 변환
PDF 파일을 JSON 파일로 변환하는 방법은 다음과 같습니다. format 옵션을 'json'으로 설정합니다.
opendataloader_pdf.convert(
input_path=['TemplateEngineIngredientPDF.pdf'],
output_dir='C:/Users/convert_pdf/',
format=['json']
)JSON 파일로 변환한 결과는 다음과 같습니다.
import json
from pathlib import Path
pdf_to_json = json.loads(Path('TemplateEngineIngredientPDF.json').read_text())
pdf_to_json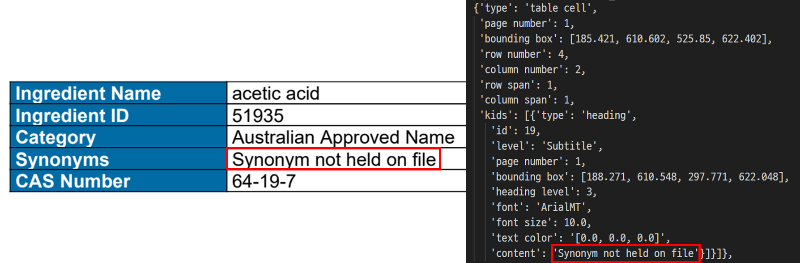
JSON 구조에 대한 주요 필드별 의미는 다음과 같습니다.
| 키 | 설명 |
| 'type': 'table cell' | 이 객체가 '표의 셀'임을 의미 |
| 'page number': 1 | PDF의 1 페이지에 위치 |
| 'bounding box': [ ] | 셀의 좌표 |
| 'row number': 4 | 표의 4번째 행 |
| 'columns number': 2 | 표의 2번째 열 |
| 'kids': [ ] | 이 셀 안에 포함된 하위 요소 |
PDF 파일 HTML 변환
PDF 파일을 HTML 파일로 변환하는 방법은 다음과 같습니다. format 옵션을 'html'로 설정합니다.
opendataloader_pdf.convert(
input_path=['TemplateEngineIngredientPDF.pdf'],
output_dir='C:/Users/convert_pdf/',
format=['html']
)HTML 파일로 변환한 결과는 다음과 같습니다.
from pathlib import Path
pdf_to_html = Path('TemplateEngineIngredientPDF.html').read_text()
print(pdf_to_html)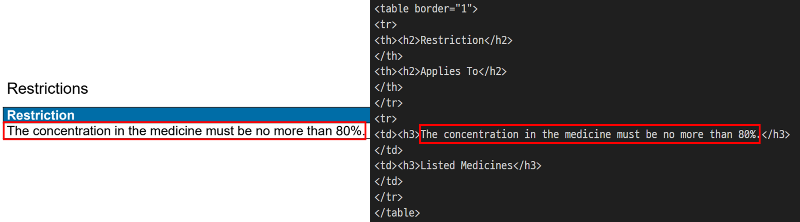
PDF 파일 마크다운 Markdown 변환
PDF 파일을 마크다운 파일로 변환하는 방법은 다음과 같습니다. format 옵션을 'markdown'으로 설정합니다.
opendataloader_pdf.convert(
input_path=['TemplateEngineIngredientPDF.pdf'],
output_dir='C:/Users/convert_pdf/',
format=['markdown']
)마크다운 파일로 변환한 결과는 다음과 같습니다.
from pathlib import Path
pdf_to_markdown = Path('TemplateEngineIngredientPDF.md').read_text()
print(pdf_to_markdown)
'Python' 카테고리의 다른 글
| [파이썬] 특정 키워드 네이버 뉴스 제목 크롤링 - BeautifulSoup (15) | 2025.10.19 |
|---|---|
| [파이썬] 데이터프레임 행, 열 선택 - iloc, loc (8) | 2025.10.04 |
| [파이썬] MongoDB JSON 데이터 import 및 기본 쿼리 - pymongo (3) | 2025.09.08 |
| [파이썬] bokeh를 활용한 인터랙티브 시각화 기초 - 꺾은선, 산점도, 막대 그래프 (0) | 2025.07.16 |
| [파이썬] 특정 조건에 해당하는 컬럼 선택 - 리스트 컴프리핸션, 정규식 (2) | 2025.07.09 |