
RAG 기초 개념 정리 - 등장 배경, 동작 과정
들어가며 | RAG의 등장 배경
이 글에서는 LLM의 한계를 보완한 RAG에 대해 소개합니다. RAG의 등장 배경, 개념부터 동작 과정까지 RAG를 이해하기 위한 기초를 설명합니다. RAG와 관련된 기술은 심화 편으로 다음 글에 이어서 설명 예정입니다.
Chat GPT, Gemini 등 우리가 사용하는 LLM은 크게 2가지 한계가 존재합니다.
첫째, “그럴듯하지만 틀린 답변”입니다. 이를 환각 Hallucination이라고 하는데, LLM은 사실을 조회하는 모델이 아니라, 다음에 올 단어를 확률적으로 예측하는 모델이기 때문입니다.
둘째, 학습 시점 이후의 정보와 회사 내부 문서, 개인 자료에 접근할 수 없습니다. 따라서, 사내에만 공개된 데이터에 관한 질문을 하면, LLM은 틀린 답변을 할 수 밖에 없습니다.
위의 문제를 해결하기 위해 등장한 개념이 RAG입니다.
RAG란?
RAG는 Retrieval-Augmented Generation의 약자로, “검색을 결합한 생성”입니다. AI가 바로 답을 만드는 대신, 먼저 관련 문서를 찾아보고 그 근거를 바탕으로 답변을 생성하는 방식입니다.
예를 들어, “우리 회사 휴가 규정 중 병가는 몇 일까지 사용 가능하니?”라고 질문한다면,
- 기존 LLM은 “일반적인 회사 규정 기준”으로 추측합니다.
- RAG는 “사내 규정 PDF”를 검색하여 해당 문단을 기반으로 답변합니다.
RAG 사례
RAG는 문서에서 추출한 정보를 기반으로 검색하므로 다음과 같이 공개된 자료가 아닌 내부 자료 검색에 적합합니다.
- 사내 문서 검색
- 규정 매뉴얼 QA
- PDF 기반 지식 시스템
RAG의 특징
RAG의 장점과 한계점은 다음과 같습니다.
장점
- 문서를 기반으로 답변하므로 정확성이 향상됩니다.
- 최신 문서를 업데이트 한다면, 최신 정보를 활용 가능합니다.
- 모델 재학습 없이 문서만 교체하면 되므로 유지보수가 용이합니다.
- 내부 문서를 활용 가능하므로 사내 시스템에 적합합니다.
한계점
- 임베딩, 벡터DB 등 파이프라인이 필요하므로 구축 비용이 발생합니다.
- 정제되지 않은 문서는 검색 품질을 저하시키므로 문서 관리가 필요합니다.
- 검색, 생성으로 응답 시간이 다소 증가합니다.
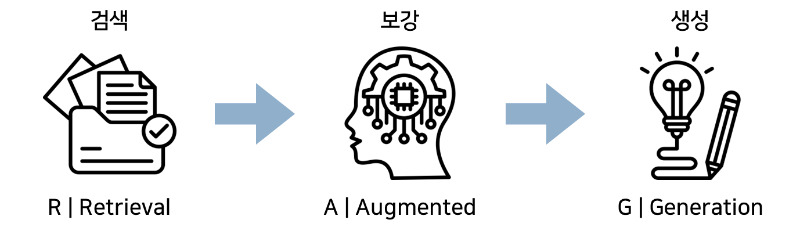
RAG의 동작 과정
RAG의 동작 과정은 다음과 같습니다.
Retrieval 검색
사내 문서, 사내 데이터베이스, 첨부파일 등 질문과 관련된 정보를 찾습니다. 정답을 “만드는 것”이 아니라 답변에 대한 근거를 찾는 것이 목적입니다. '검색' 단계의 품질이 RAG의 전체 성능을 좌우합니다.
Augmented 보강
검색해서 찾은 내용을 그대로 AI에게 함께 전달합니다. "질문"과 "관련 문서 중 일부"를 한 번에 입력합니다.
Generation 생성
마지막으로 AI는 주어진 문서 내용 안에서만 답변을 생성합니다. 따라서, 출처 문서에 없는 내용은 답변하지 않습니다.

'이론' 카테고리의 다른 글
| 네트워크 이해하기 #1 - 방향(인바운드, 아웃바운드) (0) | 2026.01.02 |
|---|---|
| [통계] 여론조사 속 통계(신뢰 수준, 표본오차) 개념 정리 (3) | 2025.12.22 |
| [검색] 키워드 서치, 시맨틱 서치, 하이브리드 서치 개념 정리 (2) | 2025.11.17 |
| [통계] 중심극한정리 Central Limit Theorem, CLT에 대하여 (4) | 2025.11.09 |
| [LLM] 토큰 Token에 대하여 - 모델이 언어를 이해하는 최소 단위 (2) | 2025.11.02 |