반응형

피벗 테이블 멀티 인덱스 해제
들어가며
파이썬에서 pivot_table을 활용하여 피벗 테이블을 생성할 때, 멀티 인덱스를 제거하는 방법을 소개합니다. 컬럼을 수동으로 입력하는 방법도 있지만, 편리하고 깔끔하게 데이터프레임을 정리할 수 있습니다.
피벗 테이블 멀티 인덱스 해제
먼저 필요한 패키지인 pandas를 설치하고 import합니다.
# pip install pandas
import pandas as pd예제 데이터로 날짜별 지역별 강수량, 적설량 데이터를 사용하겠습니다.
df = pd.read_csv('weather_sample.csv', encoding='euc-kr')
df.head()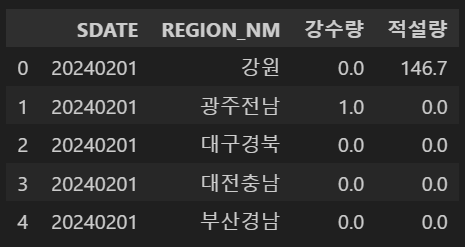
인덱스를 날짜로 설정하고, 지역별 강수량, 적설량이 나오도록 피벗 테이블을 생성하겠습니다.
df1 = df.pivot_table(index='SDATE', columns='REGION_NM', values=['강수량','적설량']).reset_index()
df1.head()
위에서 만든 피벗 테이블 df1의 컬럼을 출력하면, 다음과 같이 멀티 인덱스를 확인할 수 있습니다.
df1.columns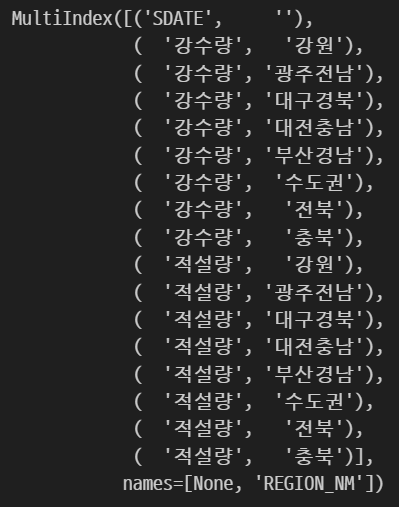
멀티 인덱스를 해제하는 방법은 다음과 같습니다. 컬럼명을 불러와서 길이를 기준으로 새로운 컬럼명을 설정합니다.
df2 = df.pivot_table(index='SDATE', columns='REGION_NM', values=['강수량','적설량']).reset_index()
df2.columns = ['_'.join([col for col in multi_col if len(col)>0]) for multi_col in df2.columns]
df2.head()
반응형
사용자 정의 함수를 작성하여 사용하면 더욱 편리합니다.
def flatten_mul_index(df):
df.columns = ['_'.join([col for col in multi_col if len(col)>0])
for multi_col in df.columns]
return df
#
df3 = df.pivot_table(index='SDATE', columns='REGION_NM', values=['강수량','적설량']).reset_index()
df3 = flatten_mul_index(df3)
df3.head()전체 코드
# pip install pandas
import pandas as pd
df = pd.read_csv('weather_sample.csv', encoding='euc-kr')
df.head()
# i)
df2 = df.pivot_table(index='SDATE', columns='REGION_NM', values=['강수량','적설량']).reset_index()
df2.columns = ['_'.join([col for col in multi_col if len(col)>0]) for multi_col in df2.columns]
df2.head()
# ii) 사용자 정의 함수 사용
def flatten_mul_index(df):
df.columns = ['_'.join([col for col in multi_col if len(col)>0])
for multi_col in df.columns]
return df
df3 = df.pivot_table(index='SDATE', columns='REGION_NM', values=['강수량','적설량']).reset_index()
df3 = flatten_mul_index(df3)
df3.head()반응형
'Python' 카테고리의 다른 글
| [파이썬] 범주형 변수 처리, 더미변수 - get_dummies, OneHotEncoder (2) | 2025.04.08 |
|---|---|
| [파이썬] 패키지 설치 자동화 스크립트 - subprocess, importlib (0) | 2025.04.07 |
| [파이썬] Unix UTC 시간 변환 - datetime, utcfromtimestamp (0) | 2025.04.05 |
| [파이썬] 파일 이동, 폴더 변경 - shutil (4) | 2025.04.04 |
| [파이썬] datetime 타입 변환/ 날짜 요소 추출(dt)/ 현재 날짜, 시간 표현 (2) | 2025.04.04 |