반응형

범주형 변수 처리, 더미변수 - get_dummies, OneHotEncoder
- 더미변수란?
- sample
- get_dummies
- OneHotEncoder
더미변수란?
범주형 변수를 수치형 변수로 만들기 위해 임의로 생성하는 변수를 의미합니다. 모델을 학습시킬 때 데이터에서 범주형 변수가 존재한다면, 모델에 직접 적용할 수 없기 때문에 해당 속성에 따라 (0:아니요, 1:예)로 구분하여 변수를 새로 생성합니다. 파이썬을 활용할 때 주로 사용하는 방법인 get_dummies와 onehotencoder가 있습니다.
sample
예를 들어, 각 id별로 선택한 과목을 나타낸 데이터프레임이 있다고 가정하겠습니다. Subject 변수를 get_dummies와 onehotencoder를 통해 더미변수를 생성하겠습니다.
df = pd.DataFrame({'id':['id_00','id_01','id_02','id_03','id_04','id_05'],
'Subject':['Korean','Korean','English','Math','Science','English']})
df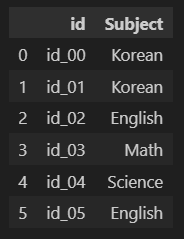
get_dummies
pandas의 get_dummies를 사용하면, 편리하게 범주형 변수를 수치형 변수로 변환할 수 있습니다. 아래 3가지 방법 중 편리한 방법을 사용하면 됩니다.
# i)
df1 = pd.concat([df.drop(['Subject'], axis=1), pd.get_dummies(df[['Subject']], dtype=int)], axis=1)
df1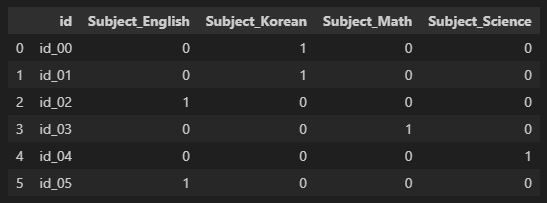
# ii)
df2 = pd.get_dummies(df,columns=['Subject'])
df2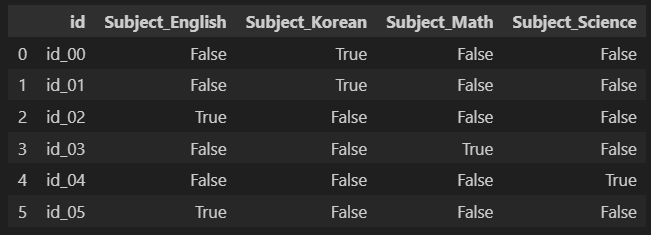
# iii)
df3 = pd.get_dummies(df,columns=['Subject'], dtype=int)
df3
반응형
OneHotEncoder
Scikit-Learn의 OneHotEncoder도 편리하게 범주형 변수를 변환할 수 있습니다. sparse는 True가 디폴트로 매트릭스로 반환하는 옵션입니다. get_dummies보다 코드가 길지만, OneHotEncoder를 사용하면 train 데이터에는 있고 test 데이터에는 없는 변수를 생성할 수 있습니다. 조금 귀찮더라도, OneHotEncoder를 추천합니다.
from sklearn.preprocessing import OneHotEncoder
onehot_encoder = OneHotEncoder(sparse=False)
dataset_onehot = onehot_encoder.fit_transform(df[['Subject']])
df2 = pd.concat([df.drop(['Subject'], axis=1),
pd.DataFrame(dataset_onehot, columns=['Subject_' + col for col in onehot_encoder.categories_[0]])]
,axis=1)
df2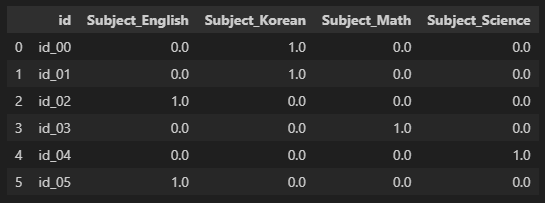
categories를 사용하면, Subject 변수의 속성을 확인할 수 있습니다.
onehot_encoder.categories_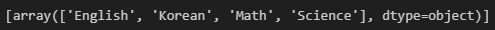
반응형
'Python' 카테고리의 다른 글
| [파이썬] 특정 경로에 폴더, directory 생성 - os, mkdir (0) | 2025.04.10 |
|---|---|
| [파이썬] 데이터 집계, 피벗 테이블 생성 - pivot_table (2) | 2025.04.09 |
| [파이썬] 패키지 설치 자동화 스크립트 - subprocess, importlib (0) | 2025.04.07 |
| [파이썬] 피벗 테이블 멀티 인덱스 해제 (4) | 2025.04.06 |
| [파이썬] Unix UTC 시간 변환 - datetime, utcfromtimestamp (0) | 2025.04.05 |