
제21대 대선 후보 검색 트렌드 시각화 - pytrends, 네이버 데이터랩
들어가며
2025년 6월 3일은 제21대 대통령 선거입니다. 선거가 일주일 앞으로 다가온 시점에서, 검색 트렌드를 분석하여 유권자들의 관심이 어디에 집중되고 있는지 파악해 보겠습니다.이 글에서는 pytrends와 네이버 데이터랩을 사용하여 대선 후보자의 검색량을 추출하고, 시각화하는 방법을 소개합니다. 분석은 장기간(5년), 단기간(1개월)로 나누어 살펴보며, 관심도의 변화를 확인해 보겠습니다.
pytrends와 네이버 데이터랩
pytrends는 Google에서 제공하는 검색 트렌드 데이터인 Google Trends를 파이썬에서 쉽게 사용할 수 있도록 도와주는 비공식 API 래퍼 라이브러리입니다. 특정 키워드에 대한 관심도 변화, 지역별 검색량, 관련 키워드 등 다양한 정보를 자동으로 수집하고 분석할 수 있어 데이터 기반 여론 분석에 유용합니다.
네이버 데이터랩은 네이버에서 제공하는 검색어 트렌드 분석 도구입니다. 네이버 사용자들의 실제 검색 데이터를 기반으로, 특정 키워드의 검색량 추이를 시간대별, 성별, 연령대별로 확인할 수 있습니다.
- 장기간 대선 후보 검색 트렌드 | 2020.05~2025.05
- 단기간 대선 후보 검색 트렌드 | 2025.03.20~2025.05.25
장기간 대선 후보 검색 트렌드 | 2020.05~2025.05
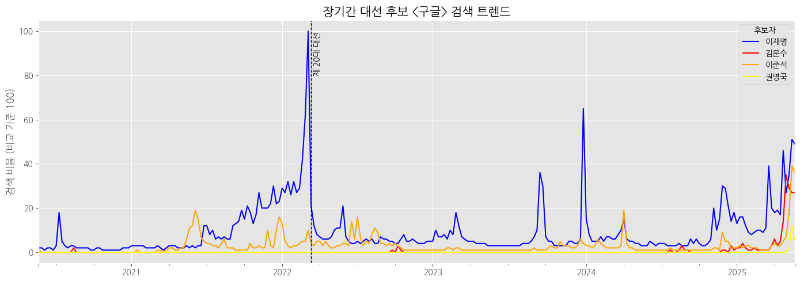
장기간 구글 검색 트렌드
약 5년 간의 구글 검색 트렌드 데이터를 추출하고 시각화하겠습니다.
import pandas as pd
from pytrends.request import TrendReq
import matplotlib.pyplot as plt
keywords = ['이재명', '김문수', '이준석', '권영국']
period = 'today 5-y'
trend_obj = TrendReq()
trend_obj.build_payload(kw_list=keywords, timeframe=period, geo='KR')
trend_df = trend_obj.interest_over_time()
colors = ['blue', 'red', 'orange', 'yellow']
plt.rc('font', family='NanumGothic')
plt.style.use('ggplot')
plt.figure(figsize=(14, 5), dpi=100)
for keyword, color in zip(keywords, colors):
trend_df[keyword].plot(label=keyword, color=color)
# '제 20대 대선' 수직선 추가
event_date = pd.to_datetime('2022-03-09')
plt.axvline(x=event_date, color='black', linestyle='--', linewidth=1)
plt.text(event_date + pd.Timedelta(days=7), plt.ylim()[1]*0.95,
'제 20대 대선', rotation=90, verticalalignment='top', fontsize=10)
plt.title('장기간 대선 후보 <구글> 검색 트렌드', fontsize=15)
plt.xlabel('')
plt.ylabel('검색 비율 (비교 기준 100)')
plt.grid(True)
plt.legend(loc='best', title='후보자')
plt.tight_layout()
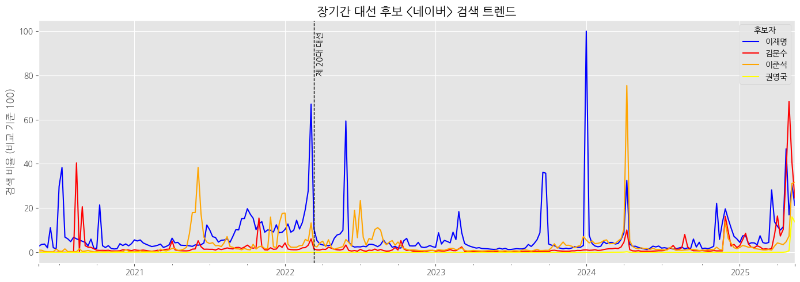
plt.show()장기간 네이버 검색 트렌드
약 5년 간의 네이버 검색 트렌드 데이터를 추출하고 시각화하겠습니다.
import os
import sys
import urllib.request
import json
import pandas as pd
import matplotlib.pyplot as plt
client_id = "YOUR_CLIENT_ID"
client_secret = "YOUR_CLIENT_KEY"
url = "https://openapi.naver.com/v1/datalab/search"
body = """
{
"startDate": "2020-05-19",
"endDate": "2025-05-19",
"timeUnit": "week",
"keywordGroups": [
{"groupName": "이재명", "keywords": ["이재명", "더불어민주당"]},
{"groupName": "김문수", "keywords": ["김문수", "국민의힘"]},
{"groupName": "이준석", "keywords": ["이준석", "개혁신당"]},
{"groupName": "권영국", "keywords": ["권영국", "민주노동당"]}
],
"device": "",
"ages": [],
"gender": ""
}
"""
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id", client_id)
request.add_header("X-Naver-Client-Secret", client_secret)
request.add_header("Content-Type", "application/json")
response = urllib.request.urlopen(request, data=body.encode("utf-8"))
response_body = response.read()
result = json.loads(response_body.decode('utf-8'))
records = []
for group in result['results']:
title = group['title']
for item in group['data']:
records.append({
"category": title,
"date": item["period"],
"ratio": item["ratio"]
})
df = pd.DataFrame(records)
df["date"] = pd.to_datetime(df["date"])
pivot_df = df.pivot(index="date", columns="category", values="ratio")
plt.rc('font', family='NanumGothic')
plt.style.use('ggplot')
plt.figure(figsize=(14, 5), dpi=100)
color_map = {
'이재명': 'blue',
'김문수': 'red',
'이준석': 'orange',
'권영국': 'yellow'
}
candidates = ['이재명', '김문수', '이준석', '권영국']
for candidate in candidates:
pivot_df[candidate].plot(label=candidate, color=color_map.get(candidate, None))
# '제 20대 대선' 수직선 추가
event_date = pd.to_datetime('2022-03-09')
plt.axvline(x=event_date, color='black', linestyle='--', linewidth=1)
plt.text(event_date + pd.Timedelta(days=7), plt.ylim()[1]*0.95,
'제 20대 대선', rotation=90, verticalalignment='top', fontsize=10)
plt.title('장기간 대선 후보 <네이버> 검색 트렌드', fontsize=15)
plt.xlabel('')
plt.ylabel('검색 비율 (비교 기준 100)')
plt.grid(True)
plt.legend(loc='best', title='후보자')
plt.tight_layout()
plt.show()장기간 검색 트렌드 시각화 결과
약 5년 간의 구글, 네이버 검색 트렌드 시각화 결과는 다음과 같습니다.
단기간 대선 후보 검색 트렌드 | 2025.03.20~2025.05.25
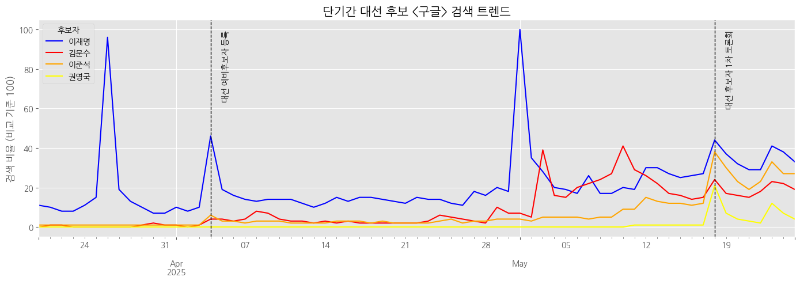
단기간 구글 검색 트렌드
약 2개월 간의 구글 검색 트렌드 데이터를 추출하고 시각화하겠습니다.
import pandas as pd
from pytrends.request import TrendReq
import matplotlib.pyplot as plt
keywords = ['이재명', '김문수', '이준석', '권영국']
trend_obj = TrendReq()
trend_obj.build_payload(kw_list=keywords, timeframe='2025-03-20 2025-05-25', geo='KR')
trend_df = trend_obj.interest_over_time()
colors = ['blue', 'red', 'orange', 'yellow']
plt.rc('font', family='NanumGothic')
plt.style.use('ggplot')
plt.figure(figsize=(14, 5), dpi=100)
for keyword, color in zip(keywords, colors):
trend_df[keyword].plot(label=keyword, color=color)
# '대선 예비후보자 등록' 수직선 추가
event_date_1 = pd.to_datetime("2025-04-04")
plt.axvline(x=event_date_1, color='black', linestyle='--', linewidth=1)
plt.text(event_date_1 + pd.Timedelta(minutes=1440), plt.ylim()[1]*0.95, '대선 예비후보자 등록', rotation=90, verticalalignment='top', fontsize=10)
# '대선 후보자 1차 토론회' 수직선 추가
event_date_2 = pd.to_datetime("2025-05-18")
plt.axvline(x=event_date_2, color='black', linestyle='--', linewidth=1)
plt.text(event_date_2 + pd.Timedelta(minutes=1440), plt.ylim()[1]*0.95, '대선 후보자 1차 토론회', rotation=90, verticalalignment='top', fontsize=10)
plt.title('단기간 대선 후보 <구글> 검색 트렌드', fontsize=15)
plt.xlabel('')
plt.ylabel('검색 비율 (비교 기준 100)')
plt.grid(True)
plt.legend(loc='upper left', title='후보자')
plt.tight_layout()
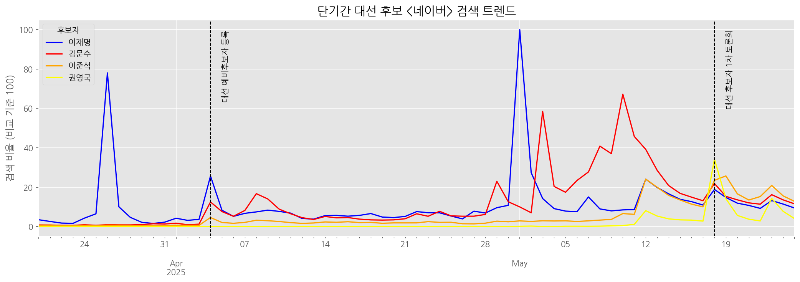
plt.show()단기간 네이버 검색 트렌드
약 2개월 간의 네이버 검색 트렌드 데이터를 추출하고 시각화하겠습니다.
import os
import sys
import urllib.request
import json
import pandas as pd
import matplotlib.pyplot as plt
client_id = "YOUR_CLIENT_ID"
client_secret = "YOUR_CLIENT_KEY"
url = "https://openapi.naver.com/v1/datalab/search"
body = """
{
"startDate": "2025-03-20",
"endDate": "2025-05-25",
"timeUnit": "date",
"keywordGroups": [
{"groupName": "이재명", "keywords": ["이재명", "더불어민주당"]},
{"groupName": "김문수", "keywords": ["김문수", "국민의힘"]},
{"groupName": "이준석", "keywords": ["이준석", "개혁신당"]},
{"groupName": "권영국", "keywords": ["권영국", "민주노동당"]}
],
"device": "",
"ages": [],
"gender": ""
}
"""
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id", client_id)
request.add_header("X-Naver-Client-Secret", client_secret)
request.add_header("Content-Type", "application/json")
response = urllib.request.urlopen(request, data=body.encode("utf-8"))
response_body = response.read()
result = json.loads(response_body.decode('utf-8'))
records = []
for group in result['results']:
title = group['title']
for item in group['data']:
records.append({
"category": title,
"date": item["period"],
"ratio": item["ratio"]
})
df = pd.DataFrame(records)
df["date"] = pd.to_datetime(df["date"])
pivot_df = df.pivot(index="date", columns="category", values="ratio")
plt.rc('font', family='NanumGothic')
plt.style.use('ggplot')
plt.figure(figsize=(14, 5), dpi=100)
color_map = {
'이재명': 'blue',
'김문수': 'red',
'이준석': 'orange',
'권영국': 'yellow'
}
candidates = ['이재명', '김문수', '이준석', '권영국']
for candidate in candidates:
pivot_df[candidate].plot(label=candidate, color=color_map.get(candidate, None))
# '대선 예비후보자 등록' 수직선 추가
event_date_1 = pd.to_datetime("2025-04-04")
plt.axvline(x=event_date_1, color='black', linestyle='--', linewidth=1)
plt.text(event_date_1 + pd.Timedelta(minutes=1440), plt.ylim()[1]*0.95, '대선 예비후보자 등록', rotation=90, verticalalignment='top', fontsize=10)
# '대선 후보자 1차 토론회' 수직선 추가
event_date_2 = pd.to_datetime("2025-05-18")
plt.axvline(x=event_date_2, color='black', linestyle='--', linewidth=1)
plt.text(event_date_2 + pd.Timedelta(minutes=1440), plt.ylim()[1]*0.95, '대선 후보자 1차 토론회', rotation=90, verticalalignment='top', fontsize=10)
plt.title('단기간 대선 후보 <네이버> 검색 트렌드', fontsize=15)
plt.xlabel('')
plt.ylabel('검색 비율 (비교 기준 100)')
plt.grid(True)
plt.legend(loc='upper left', title='후보자')
plt.tight_layout()
plt.show()단기간 검색 트렌드 시각화 결과
약 2개월 간의 구글, 네이버 검색 트렌드 시각화 결과는 다음과 같습니다.
'Python' 카테고리의 다른 글
| [파이썬] OCR을 활용한 PDF/이미지 텍스트 추출 - pytesseract (0) | 2025.06.13 |
|---|---|
| [파이썬] 엑셀 통합파일(.xlsx) 시트별 저장 - ExcelWriter (4) | 2025.06.07 |
| [모니터링] 파이썬을 활용한 로그 기록 - logging, logger (2) | 2025.05.20 |
| [파이썬] 결측값 확인 및 처리 - 행/열별 결측값 개수, isna(), fillna() (8) | 2025.05.19 |
| [파이썬] pyfiglet을 활용한 ASCII ART 아스키 아트 (2) | 2025.05.13 |