
결측값 확인 및 처리 - 행/열별 결측값 개수, isna(), fillna()
들어가며
데이터 분석을 하기 전, 결측값에 대한 처리는 매우 중요합니다. 분석의 결과에 영향을 미치는 것뿐만 아니라 신뢰성 저하의 문제도 있습니다. 데이터 전처리 과정에서 어떤 변수에서 결측이 존재하는지 확인하고, 결측값을 처리하는 방법을 소개합니다. 먼저, 결측값이 존재하는 컬럼과 행/열별 결측값 개수를 분석하고, 결측에 대한 처리 순서로 진행합니다.
- 예제 데이터
- 결측값 확인
- 결측값 처리
예제 데이터
이 글에서 활용할 데이터는 임의로 생성된 난수입니다. 결측값을 전체의 30% 비율로 랜덤하게 삽입했습니다. 아래 파일을 다운로드하여 연습해 보세요.
먼저 필요한 패키지인 pandas를 import 하고, 데이터를 불러옵니다.
# pip install pandas
import pandas as pd
df = pd.read_csv('null_sample.csv')
print('df shape: ', df.shape)
df.head()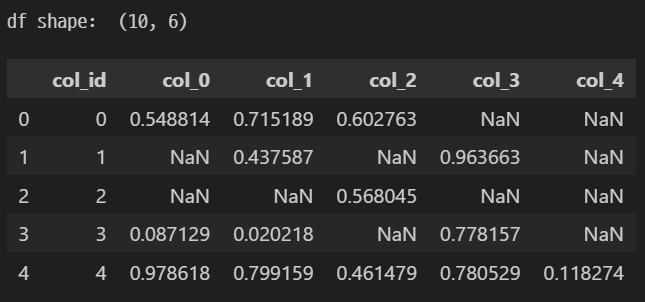
결측값 확인
1) 결측값이 존재하는 컬럼 확인
데이터프레임에서 결측값이 존재하는 컬럼을 확인하는 방법은 다음과 같습니다.
df.columns[df.isna().any()]
2) 열별 결측값 개수
결측값이 존재하는 컬럼을 확인했다면, 구체적으로 결측값이 몇 개 존재하는지 확인합니다. 열별 결측값 개수는 다음과 같습니다. 각 컬럼에 대한 결측값의 개수를 확인할 수 있습니다.
df.isna().sum()
위의 코드에서 sum()을 추가하면 전체 데이터프레임의 결측값 개수를 확인할 수 있습니다.
print('총 결측값 개수: ', df.isna().sum().sum())
3) 행별 결측값 개수
다음은 행별 결측값 개수를 확인해 보겠습니다. 행별 결측값 개수를 합산한 na_cnt 컬럼을 생성합니다. na_cnt 컬럼을 합한 결과, 즉, 전체 데이터프레임의 결측값은 총 24개입니다.
df['na_cnt'] = df.isna().sum(1)
print('na_cnt sum: ', df.na_cnt.sum())
df.head()
결측값 처리
1) 결측값 평균으로 대체
결측값을 각 컬럼에 대한 평균값으로 대체해 보겠습니다. 아래 2가지 방법 중 편한 방법을 사용하면 됩니다.
# i)
df1 = df.copy()
df1['col_0'] = df1['col_0'].fillna(df1['col_0'].mean())
df1['col_1'] = df1['col_1'].fillna(df1['col_1'].mean())
df1['col_2'] = df1['col_2'].fillna(df1['col_2'].mean())
df1['col_3'] = df1['col_3'].fillna(df1['col_3'].mean())
df1['col_4'] = df1['col_4'].fillna(df1['col_4'].mean())
print('총 결측값 개수: ', df1.isna().sum().sum())
# ii)
col_fill_null = {'col_0' : df.col_0.mean(),
'col_1' : df.col_1.mean(),
'col_2' : df.col_2.mean(),
'col_3' : df.col_3.mean(),
'col_4' : df.col_4.mean()}
df2 = df.fillna(col_fill_null)
print('총 결측값 개수: ', df2.isna().sum().sum())
df2.head()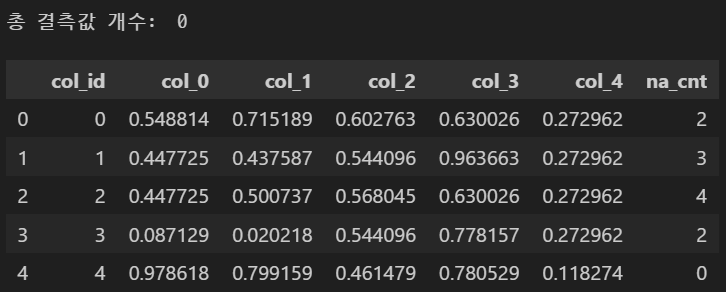
2) 컬럼별 결측값 처리
평균값 외에도 중앙값, 앞/뒤 값의 평균을 계산하는 보간법, 일괄적으로 1개의 값으로 대체도 가능합니다.
col_fill_null = {'col_0' : df.col_0.mean(), # 평균
'col_1' : df.col_1.interpolate(), # 보간법
'col_2' : 'Unknown',
'col_3' : 0,
'col_4' : df.col_4.median()} # 중앙값
df3 = df.fillna(col_fill_null)
print('총 결측값 개수: ', df3.isna().sum().sum())
df3.head()
3) ffill 결측값 처리
결측값을 처리할 때, ffill을 사용하면 전체 데이터프레임의 각각의 결측값에 대해서 앞 행의 값으로 대체할 수도 있습니다. 하지만 만약 결측값이 앞부분에 존재한다면, 결측 보정이 되지 않는다는 단점이 있습니다.
df4 = df.copy()
df4.fillna(method = 'ffill', inplace = True)
print('총 결측값 개수: ', df4.isna().sum().sum())
df4.head()
4) bfill 결측값 처리
결측값을 처리할 때, bfill을 사용하면 전체 데이터프레임의 각각의 결측값에 대해서 뒤 행의 값으로 대체할 수도 있습니다. bfill은 결측값이 뒷부분에 존재한다면, 결측 보정이 되지 않는다는 단점이 있습니다.
df5 = df.copy()
df5.fillna(method = 'bfill', inplace = True)
print('총 결측값 개수: ', df5.isna().sum().sum())
df5.head()
전체 코드
import pandas as pd
df = pd.read_csv('null_sample.csv')
print('df shape: ', df.shape)
df.head()
## 결측값 존재 컬럼 확인
df.columns[df.isna().any()]
## 열별 결측값 개수
df.isna().sum()
## 행별 결측값 개수
df['na_cnt'] = df.isnull().sum(1)
print('na_cnt sum: ', df.na_cnt.sum())
## 결측값 처리
# i)
df1 = df.copy()
df1['col_0'] = df1['col_0'].fillna(df1['col_0'].mean())
df1['col_1'] = df1['col_1'].fillna(df1['col_1'].mean())
df1['col_2'] = df1['col_2'].fillna(df1['col_2'].mean())
df1['col_3'] = df1['col_3'].fillna(df1['col_3'].mean())
df1['col_4'] = df1['col_4'].fillna(df1['col_4'].mean())
# ii)
col_fill_null = {'col_0' : df.col_0.mean(),
'col_1' : df.col_1.mean(),
'col_2' : df.col_2.mean(),
'col_3' : df.col_3.mean(),
'col_4' : df.col_4.mean()}
df2 = df.fillna(col_fill_null)
## 컬럼별 결측값 처리
col_fill_null = {'col_0' : df.col_0.mean(), # 평균
'col_1' : df.col_1.interpolate(), # 보간법
'col_2' : 'Unknown',
'col_3' : 0,
'col_4' : df.col_4.median()} # 중앙값
df3 = df.fillna(col_fill_null)
## 결측값 처리 - ffill
df4 = df.copy()
df4.fillna(method = 'ffill', inplace = True)
print('총 결측값 개수: ', df4.isna().sum().sum())
## 결측값 처리 - bfill
df5 = df.copy()
df5.fillna(method = 'bfill', inplace = True)
print('총 결측값 개수: ', df5.isna().sum().sum())
'Python' 카테고리의 다른 글
| [파이썬] CCTV 이미지를 활용한 이미지 객체 탐지 - 박스 표시, yolov5 (4) | 2024.10.22 |
|---|---|
| [파이썬] 데이터프레임 형태 변환 - pandas, melt (0) | 2024.10.21 |
| [파이썬] 데이터 집계 및 요약 - pandas, pivot_table, aggfunc (0) | 2024.10.14 |
| [파이썬] 파이썬을 활용한 이미지 배경 제거 - PIL, rembg (1) | 2024.10.07 |
| [파이썬] 데이터프레임 행, 열 선택 - iloc, loc (2) | 2024.10.07 |