
API를 활용한 유튜브 크롤링 - 댓글, 조회수, 좋아요 수 수집
들어가며
이 글에서는 유튜브의 댓글, 조회수, 좋아요 수를 크롤링하는 방법을 소개합니다. Google의 YouTube Data API v3을 활용하여 공식적으로 안정적인 데이터 수집이 가능합니다.
본격적인 데이터 수집을 하기 전에 구글 클라우드에서 API KEY를 발급받는 과정부터 시작합니다. 그리고 검색 쿼리에 해당하는 영상ID를 추출 후, 영상의 댓글, 조회수, 좋아요 수를 수집합니다. 마지막 단계에서는 크롤링 자동화를 위해 영상ID, 댓글, 지표 추출을 모두 사용자 정의 함수로 구현합니다.
Google YouTube Data API v3는 기본적으로 무료로 제공되지만, 일일 사용량 쿼터 제한이 있습니다. 제한을 초과할 경우, 과금이 발생할 수 있으므로 유의해야 합니다.
구글 API KEY 생성
구글 클라우드에 접속하여 '프로젝트 선택' → '새 프로젝트' 를 클릭합니다.


프로젝트 이름을 설정하고 '만들기'를 클릭하면 새로운 프로젝트가 생성됩니다.

API 및 서비스를 클릭합니다.

API 및 서비스 → API 라이브러리를 클릭하여 Youtube Data API v3를 활성화합니다.
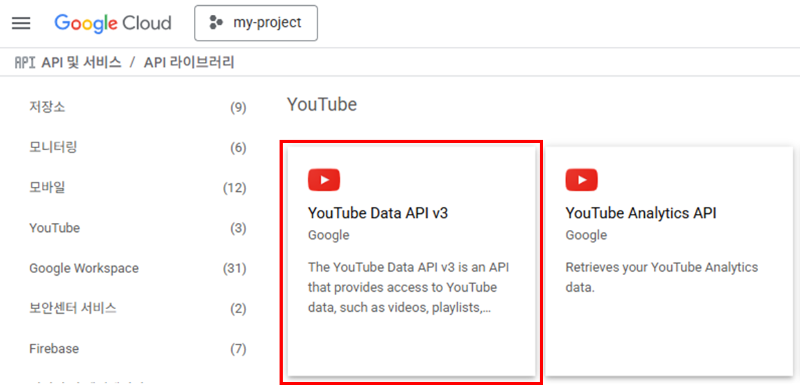
'API 키'를 클릭하여 API 키를 발급받습니다.
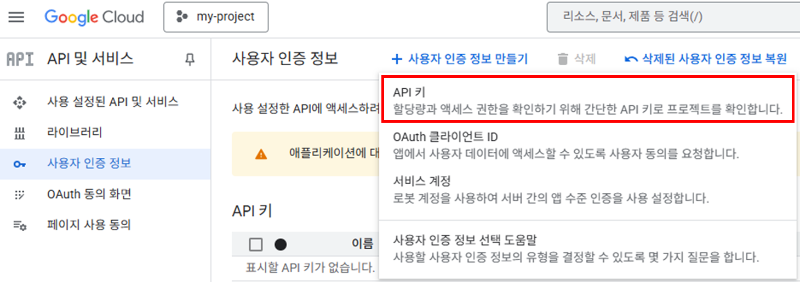
발급받은 API 키는 코드에서 사용해야 하므로, 개인 정보 보호를 위해 안전한 곳에 보관해야 합니다.

API 클라이언트 생성
먼저 필요한 패키지를 설치하고, import 합니다.
# ! pip install google-api-python-client
from googleapiclient.discovery import build위에서 발급받은 API KEY로 API에 요청을 보낼 수 있는 클라이언트 객체를 생성합니다. youtube 변수가 다음과 같은 결과를 출력한다면, 정상 실행됐음을 의미합니다. 즉, 유튜브 서버에 연결할 수 있는 준비를 완료했습니다.
api_key = "YOUR_API_KEY"
youtube = build("youtube", "v3", developerKey=api_key)
youtube
유튜브 영상ID 추출
데이터를 수집할 수 있는 환경 세팅은 모두 완료됐습니다. 이제 search 함수를 사용하여 유튜브 영상ID를 추출하겠습니다.
'부산 여행'에 대한 유튜브 검색 결과는 다음과 같습니다. maxResults를 3으로 설정하여, 총 3개의 영상ID를 추출합니다. 여기서 order 옵션에 대한 디폴트는 관련도 순입니다. 다른 옵션 값으로 date(최신 업로드 순), viewCount(조회수 많은 순), rating(평점 높은 순), title(영상 제목 순)이 있습니다.
query = '부산 여행'
request = youtube.search().list(
q=query,
part="snippet",
maxResults=3,
# order="date",
type="video"
)
response = request.execute()
videos = []
for item in response["items"]:
video_id = item["id"]["videoId"]
title = item["snippet"]["title"]
videos.append((video_id, title))
videos
유튜브 영상 댓글 추출
commentThreads 함수를 활용하여 위에서 추출한 영상ID 1개에 대한 댓글을 추출하겠습니다. maxResults를 10으로 설정하여, 10개의 댓글을 출력한 결과는 다음과 같습니다.
video_id = 'itlrFCBVzoM'
comments = []
request = youtube.commentThreads().list(
part="snippet",
videoId=video_id,
maxResults=10,
textFormat="plainText"
)
response = request.execute()
for item in response.get("items", []):
comment = item["snippet"]["topLevelComment"]["snippet"]["textDisplay"]
comments.append(comment)
comments
유튜브 영상 조회수, 좋아요 수, 댓글 수 추출
part 옵션을 'statistics'로 변경하여 유튜브 영상에 대한 조회수, 좋아요 수, 댓글 수를 추출하겠습니다. viewCount, likeCount, commentCout는 각각 조회수, 좋아요 수, 댓글 수를 의미합니다.
video_id = 'itlrFCBVzoM'
request = youtube.videos().list(
part="statistics",
id=video_id
)
response = request.execute()
stats = response["items"][0]["statistics"]
view_count = int(stats.get("viewCount", 0))
like_count = int(stats.get("likeCount", 0))
comment_count = int(stats.get("commentCount", 0))
print(f"조회수: {view_count}")
print(f"좋아요 수: {like_count}")
print(f"댓글 수: {comment_count}")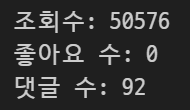
유튜브 크롤링 자동화
위의 유튜브 영상ID, 댓글, 조회수, 좋아요 수 등의 지표 출력을 한 번에 실행하는 자동화 함수는 다음과 같습니다. 검색 쿼리만 입력하면, 위에서 추출한 모든 정보를 한 번에 수집할 수 있습니다.
from googleapiclient.discovery import build
api_key = "YOUR_API_KEY"
youtube = build("youtube", "v3", developerKey=api_key)
# 유튜브 영상ID 추출
def search_youtube_videos(query, max_results=3):
request = youtube.search().list(
q=query,
part="snippet",
maxResults=max_results,
type="video"
)
response = request.execute()
videos = []
for item in response["items"]:
video_id = item["id"]["videoId"]
title = item["snippet"]["title"]
videos.append((video_id, title))
return videos
# 유튜브 영상 댓글 추출
def get_video_comments(video_id, max_results=5):
comments = []
request = youtube.commentThreads().list(
part="snippet",
videoId=video_id,
maxResults=max_results,
textFormat="plainText"
)
response = request.execute()
for item in response.get("items", []):
comment = item["snippet"]["topLevelComment"]["snippet"]["textDisplay"]
comments.append(comment)
return comments
# 유튜브 영상 지표 추출
def get_video_statistics(video_id):
request = youtube.videos().list(
part="statistics",
id=video_id
)
response = request.execute()
stats = response["items"][0]["statistics"]
view_count = int(stats.get("viewCount", 0))
like_count = int(stats.get("likeCount", 0))
comment_count = int(stats.get("commentCount", 0))
return view_count, like_count, comment_count
## 자동화 함수 실행
query = "부산 여행"
videos = search_youtube_videos(query, max_results=3)
for vid, title in videos:
print(f"[제목] {title}")
comments = get_video_comments(vid)
print(f"→ 댓글 수집 완료: {comments[0]}\n")
view_count, like_count, comment_count = get_video_statistics(vid)
print(f"→ 조회수: {view_count}개")
print(f"→ 좋아요 수: {like_count}개")
print(f"→ 댓글 수: {comment_count}개\n")'Python' 카테고리의 다른 글
| [파이썬] pyfiglet을 활용한 ASCII ART 아스키 아트 (2) | 2025.05.13 |
|---|---|
| [파이썬] 이미지 객체 탐지 - CCTV 이미지를 활용한 교통량 검지 (9) | 2025.05.01 |
| [파이썬] 날짜 차이 계산, 날짜 범위 리스트 생성 - DateOffset, date_range (5) | 2025.04.27 |
| [파이썬] 데이터프레임 행 반복 처리 - iterrows, itertuples (4) | 2025.04.24 |
| [파이썬] 토이 프로젝트 - 테니스 코트 정보 확인(날씨 예보, 주차 등) (4) | 2025.04.23 |