
텍스트 임베딩 Text Embedding 개념 정리
들어가며
자연어 처리에서 텍스트 데이터를 컴퓨터가 이해하고 활용할 수 있도록 변환하는 과정은 필수적입니다. 텍스트 임베딩은 단어, 문장 또는 문서를 고정된 차원의 벡터로 변환하는 방법입니다. 이 글에서는 텍스트 임베딩에 대한 개념과 응용 분야 그리고 종류에 대해 소개합니다.
- 텍스트 임베딩이란?
- 텍스트 임베딩 응용 분야
- 텍스트 임베딩의 종류
텍스트 임베딩이란?
텍스트 임베딩 Text Embedding은 단어나 문장을 수치 벡터로 변환하는 방법입니다. 컴퓨터는 문자를 이해할 수 없기 때문에 텍스트를 수치형 데이터로 변환해야 합니다. 단순히 문자를 숫자로 바꾸는 것이 아니라, 텍스트의 의미적(semantics) 및 문맥적(contextual) 정보를 반영한 다차원 벡터 공간으로 표현합니다.
즉, '임베딩'은 텍스트의 의미를 보존하면서 고정된 차원의 벡터로 변환하는 과정이며, 이 벡터는 머신러닝이나 딥러닝 모델에서 사용할 수 있습니다.
텍스트 임베딩 응용 분야
텍스트를 벡터로 변환하는 작업을 통해 다양한 응용이 가능합니다. 텍스트 임베딩 응용 분야는 다음과 같습니다.
1. 텍스트 검색 및 정보 검색
사용자의 질문과 데이터베이스의 문장 간 유사도를 비교하여 관련 문장을 제공합니다. 예를 들어서, "여름 휴가지 추천" 을 검색했을 때, 여름 휴가지 관련 문장을 검색하여 사용자에게 제공합니다.
2. 텍스트 분류
스팸 메일 분류, 감성 분석, 토픽 분류 등에 활용할 수 있습니다. 예를 들어서 "이 영화 정말 재밌어"라는 문장을 '긍정 감정'으로 분류하는 것과 같이 텍스트의 감정이나 의견을 분류할 수 있습니다.
3. 챗봇 및 AI 어시스턴트
사용자 질문과 유사한 질문을 찾거나, 문맥을 이해하는 챗봇을 구현할 수 있습니다. 사용자의 입력 텍스트를 이해하고, 적절한 응답을 생성하는 데 활용합니다.
4. 기계 번역 & 문서 요약
문장을 벡터화한 후, 의미가 유사한 문장을 찾아 번역하거나 요약이 가능합니다. 언어 간의 의미적 관계를 반영한 임베딩을 통해 더 자연스러운 번역 결과를 생성합니다.
텍스트 임베딩의 종류
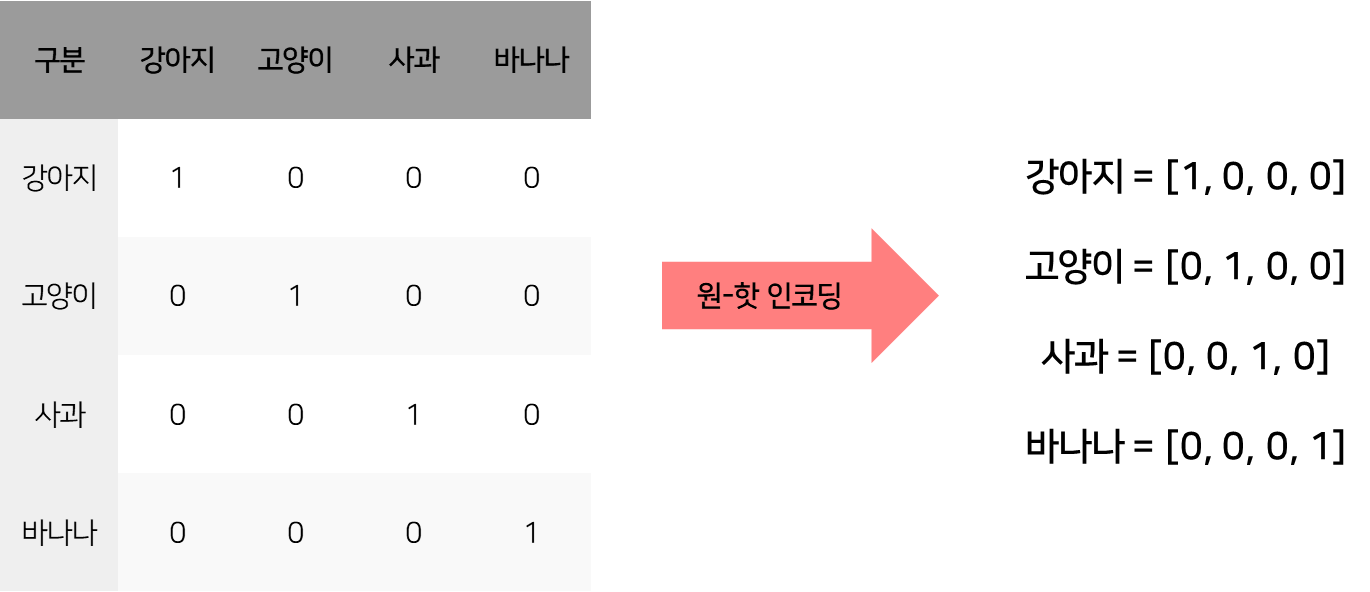
1. 원-핫 인코딩 One-Hot Encoding
가장 간단한 방법으로, 단어 리스트 내의 각 단어에 대해 고유한 인덱스를 부여하고, 해당 인덱스만 1로 설정한 벡터를 생성합니다. 하지만, 단어 간 의미 관계를 반영하지 못하고, 단어 개수가 많아지면 벡터의 크기가 너무 커지는 문제가 있습니다.
2. 워드 임베딩 Word Embedding
단어를 고정된 크기의 벡터로 변환하는 방법입니다. 단어 간의 의미적 유사성을 반영할 수 있으며, 대표적인 방법으로 Word2Vec, GloVe, FastText 등이 있습니다. 모델이 단어 간 관계를 학습하여 자동으로 벡터를 구성할 수 있습니다. 하지만, 문맥을 반영하지 못한다는 단점이 있습니다. 예를 들어서, '배'가 과일인지, 배(boat)인지 구별이 불가능합니다.

3. 문장 임베딩 Sentence Embedding
단어 임베딩보다 한 단계 발전하여 문장 전체를 하나의 벡터로 변환하는 방법입니다. 대표적인 방법으로 BERT, Sentence-BERT(S-BERT), USE(Universal Sentence Encoder) 등이 있습니다. 한 문장을 하나의 벡터로 변환하여, 문장 간 유사도 비교가 가능합니다. 문맥을 반영하여 같은 의미의 문장을 유사한 벡터로 변환하고, 긴 문장 또한 하나의 벡터로 요약 가능하지만 계산량이 많다는 단점이 있습니다.

'이론' 카테고리의 다른 글
| [Algorithm] 회귀 분석 - Regression Analysis (0) | 2025.04.19 |
|---|---|
| [이론] 클러스터링 평가 지표 - ARI, Confusion Matrix (0) | 2025.03.12 |
| [NLP] 코사인 유사도 Cosine Similarity 개념 정리 (4) | 2025.03.05 |
| [NLP] 자연어 처리 입문을 위한 개념 정리- NLP, LLM (3) | 2025.02.17 |
| [NLP] 자카드 유사도 Jaccard Similarity 개념 정리 (4) | 2025.02.13 |